-
인공지능 데이터 셋 현황과 향후 과제 - 한상기 대표(테크 프런티어) Vol 12. 교통의 미래, 자율주행을 위한카테고리 없음 2021. 9. 23. 00:01
자율주행과 지능형 교통 시스템의 운영을 위해 갖추어야 할 데이터 세트는 매우 다양하다.기본적으로 도로 주변을 감지하는 데이터가 있다.
여기에는 도로에서 얻어지는 차량의 속도, 교통량, 흐름에 대한 것이 포함된다. 두 번째는 차량 내외부의 센싱을 통해 얻을 수 있는 데이터로 다양한 센서와 내부 장착장비에서 얻을 수 있다. 세 번째로, 협력적 탐사이며, 전체의 교통 시스템을 이용하는 다른 유저로부터 얻을 수 있는 정보이다. 넷째는 외부 데이터원에서 얻는 것으로 날씨, 달력, 예정된 행사, 사회경제적, 그리고 인구통계학적 데이터이다. 마지막으로 대중교통 노선과 시간표, 지자체 자전거 대여 서비스와 관련된 데이터처럼 구조적 또는 정적 데이터가 포함돼 있다.
인공지능 활용 영역에서 가장 관심을 갖는 교통 분야는 자율주행이다. 이를 해결하기 위해 많은 기업이 학습을 위한 데이터셋을 만들고 있다. 이것에 대한 투자는, 국내의 공공 영역을 시작으로 민간에서도 활발하게 행해지고 있다.
특히 자율주행을 위한 오픈 데이터 세트 중 알파벳 자회사 웨이모(Waymo)와 승차공유 서비스인 리프트(Lyft)의 데이터 세트가 잘 알려져 있다. 두 기업 모두 자신의 데이터셋을 기반으로 하는 도전도 열려 더욱 흥미롭다.
웨이모 데이터 세트는 간단한 등록 절차를 밟으면 액세스 할 수 있어 공개한 데이터 세트에는 모션 데이터 세트와 인지 데이터 세트의 2가지가 있다. 이들 데이터는 다운로드하거나 구글 클라우드 API를 통해 액세스할 수 있다. 물론 기허브로 역시 데이터 소개와 접속이 가능하다.2)
웨이모 오픈 데이터 셋은 2019.8월에 출시되었으며, 당초에는 1950 세그먼트에 대한 고해상도 센서 데이터와 레이블을 갖춘 퍼셉션 데이터 셋이었다. 21년 3월 업데이트에 따르면 추가로 확장된 모션 데이터셋은 10만 개 이상의 세그먼트에 대한 3차원 지도와 개체 궤적으로 구성됐다.

그림 1 웨이모션 데이터 세트 샘플 중 사이클리스트 3차원 데이터 [출처: 깃발 허브] 2021년 웨이모는 4개의 도전을 구성해 모션 예측, 상호작용 예측, 실시간 3D 탐지, 실시간 2D 탐지와 같은 주제로 진행하고 있다. 모션 예측은 주어진 에이전트의 과거 1초간 해당 장소에서의 트랙으로 최대 8개 에이전트의 다음 8초간 위치를 예측하는 문제이다. 상호작용 예측은 같은 조건을 기초로 상호작용 하는 2개의 에이전트의 8초 후의 위치를 예측하는 과제이다. 실시간 3차원 탐지는 주어진 3개의 라이더 이미지와 관련된 카메라 이미지로 장면에 있는 개체를 탐지한 3차원의 곧은 박스세트를 만든다.

그림 2 웨이모의 2021년 챌린지 소개 [출처: 웨이모] 리프트는 2019년 '레벨 5'라는 자율주행을 위한 데이터 세트를 공개했다.여기에는 사람이 손으로 레이블한 5만 5,000개 이상의 3차원 프레임, 7개의 카메라와 최대 3개의 라이더로부터 얻은 데이터, 주행 가능한 도로 표면 지도, 도로 차선, 횡단 보도 등을 포함한 고해상도 공간 세만틱 지도를 포함한다.
리프트가 생각하는 자율주행 길은 센서 입력과 지도를 통해 교통 에이전트를 탐지하는 인지 과정, 에이전트의 모션을 예측하는 모션 예측, 그리고 자율주행 차량이 선택하는 경로를 결정하는 경로 계획 과정에서 이루어진다. 이에 따라 데이터 세트를 인지 데이터 세트와 예측 데이터 세트로 나누었다.
먼저 인지 데이터 셋은 다양한 영역의 센서에서 얻어지는 원천 데이터로 다른 자동차, 보행자, 교통신호 등에 대한 것이며 리프트 자율주행 차량에서 수집한 라이더와 카메라에 입력된 것을 모았다. 여기에는 130만 개의 3D 어노테이션, 3만 개의 라이더포인트 클라우드, 60분에서 90분간의 정경을 담은 350개 이상의 장면 데이터가 있다.

그림3. 리프트 인디케이터 세트 샘플 이들 데이터는 모셔널(Motional)의 뉴씬즈(NuScenes) 데이터 포맷으로 제공된다. 이는 과거 작업과의 호환성을 보장하기 위한 것으로 리프트가 독자적으로 맞춤 제작한 뉴씬즈 개발 키트도 함께 제공하고 있다.
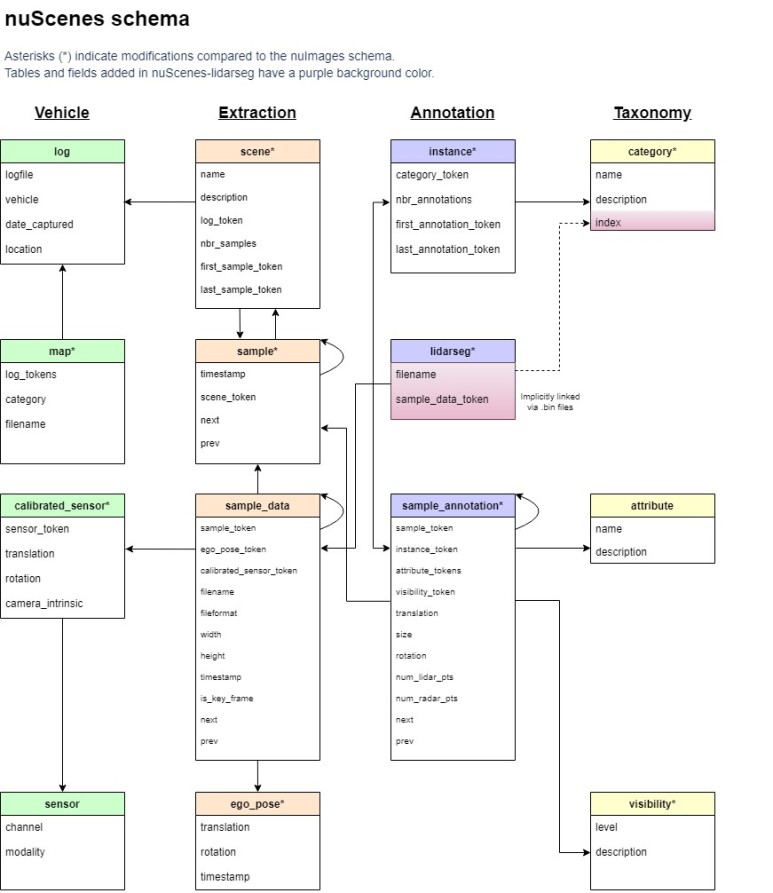
그림 4 뉴씬즈 데이터 스키마 [출처 : 뉴씬즈] 리프트의 모션 예측 데이터 세트는 자동차, 사이클 리스트, 보행자, 기타 교통 에이전트의 움직임에 대한 로그 데이터이다. 이는 자동차의 라이더, 카메라, 레이더 데이터를 인지시스템을 통해 처리한 데이터로 모션 예측 모델을 학습하는 데 활용할 수 있다. 여기에는 1,000시간 이상의 교통 에이전트의 움직임, 23개 차량에서 수집한 16,000마일의 데이터, 15,000개의 시멘틱 맵 어노테이션을 포함하고 있다. 이들을 종합하면 17만 개의 씬으로 구성되어 있는 것으로, 각 씬은 주어진 특정 시간에 차량주위의 상황상태를 인코딩한 것이다. 데이터셋은 잘(zarr) 포맷4로 제공하며 이를 읽기 위한 파이슨 소프트웨어 키트도 제공한다.
리프트는 2019년 11월부터 1년간 총상금 2만5,000달러를 들여 3D 개체 탐지를 위한 캐글 챌린지도 운영했는데 여기에 546개 팀이 참가했다. 우승자는 Neurl PS2019에서 챌린지 수상작을 발표했다. 당시 라이더, 이미지, 맵 등의 데이터 파일을 제공했다. 2020년 11월에는 모션 예측 모델을 위한 캐글 챌린지를 총상금 3만달러를 들여 실시했으며, 이때는 945개 팀이 참가했다.

그림 5. 리프트 예측 데이터 세트 샘플 일반에 공개한 자동주행을 위한 대규모 데이터세트의 하나는 앞에서 서술한 뉴 신즈데이터세트이다. 2019년 3월 모셔널 팀이 공개한 것으로 미국 보스턴과 싱가포르에서 1000개의 운전 장면을 모아 복잡하고 도전적인 운전 환경을 담고 있다. 수동으로 선정한 20초 장면은 각각 다양하고 흥미로운 운전 과정, 교통 상황, 예측하지 못한 행동을 보여주기 위해 선택했다.
개체 탐지와 트래킹을 위해 23개의 개체 클래스로 어노테이션하여 각각 3D 바운딩 박스로 표현하였다. 전체 데이터 셋은 140만 개의 카메라 이미지, 3만 9,000개의 라이인 데이터, 140만 개의 레이더 데이터, 4만 개의 키 프레임 안에 140만 개의 개체 바운딩 박스로 구성되어 있다. 또한 맵 데이터, 원천 센서 데이터 등도 공개할 예정이다. 2019년 CVPR에서 이 데이터셋으로 3D탐지 도전을 진행한 바 있다.
2020년 7월 뉴씬즈-라이더 세그(nu Scenes-lidarseg)라는 데이터가 공개됐고 여기에는 각 키 프레임에서 각 라이더 포인트를 어노테이션해 32개의 가능한 시멘틱 레이블을 달았다. 결과적으로 이 데이터 셋은 140억 개의 어노테이션된 포인트를 포함하며 4만 개의 포인트 클라우드와 1,000개의 장면(850개는 학습과 검증, 150개의 테스트용)으로 구성된다.
자율주행 교통 분야에 사용된 데이터셋으로는 아스틱스(Astyx) HiRes2019 구글 랜드맥스(Landmarks) KITTI 데이터셋 판다세(Pandset) 등이 있다. 카메라 기반의 개체 탐지를 위한 시티스케이프(Cityscapes), 머필러리 비스터스(Mappillary Vistas), 아폴로 스케이프(Apolloscapes), 버클리 딥 드라이드(Deep Drive) 등의 데이터 셋도 있다.
자율주행을 직접 언급하지는 않았지만 교통영역에서 인공지능 개발을 위해 활용할 수 있는 다양한 데이터셋도 존재한다. 주로 일반교통환경과 도시별 대중교통에 관한 데이터, 우버와 같은 라이드 공유 데이터 등의 추가적인 데이터 세트로 활용할 수 있다.
2018년 네이처 사이언티픽 데이터가 펴낸 논문에서는 25개 도시의 대중교통망 데이터셋을 소개했다.유럽의 주요 도시와 호주의 도시를 주로 포함하고 있었으며 미국 디트로이트와 캐나다 위니펙도 포함되어 있었다. 이러한 데이터는 모두 「일반 교통 피드 명세(GTFS:General Transit Feed Specification)」라고 하는 표준 오픈 포맷으로 공개하고 있다. 각 도시의 교통당국이 공개한 경로와 일정한 데이터가 담겨 STFS 피드를 구성하는 CSV 텍스트 파일로 제공된다.
논문 저자들은 전 세계 25개 도시에서 관련 GTF의 피드를 내려받아 이를 데이터베이스에 저장하고 다중 소스에서 나온 피드를 맞췄다. 정류장마다 GTFS 데이터가 이동 시간에 대한 정보를 모두 갖고 있지 않기 때문에 이를 다시 정류장 간 거리로 강화했다. 이때는 오픈스트리트 맵(Open Street Map) 프로젝트를 통해 길에 대한 네트워크를 활용했다. 이 데이터 셋은 대중교통기관의 네트워크 분석과 라우팅 알고리즘의 계산방식을 개발하기 위한 테스트베드로 사용할 수 있다.

그림 6 도시 하나에 대해 데이터 처리를 위한 파이프라인 한편 우버는 우버 무브먼트라는 이름으로 사람들의 이동경로 패턴을 공개하고 있다. 2020년 7월에는 뉴모빌리티 히트맵을 통해서 8개 도시의 점프 바이크와 스쿠터(킥보드)의 움직임을 보였다.

그림 7. 우버 무브먼트에서 보여주는 샌프란시스코의 오토바이 사용 패턴 [출처 : 우버] 도시의 모빌리티 사용현황도 볼 수 있어 향후 도시교통계획을 수립할 때 매우 중요한 자료가 되는 데이터이다. 우버는 전 세계 55개 도시의 우버 사용 패턴을 볼 수 있는 무브먼트 페이지도 만들어 공개하고 있다.
카글에서는 교통 분야의 데이터 세트 중 규모가 큰 것으로 약 225개가 존재하는데, 자동차 이미지 데이터, 합성한 번호판 데이터, 각 도시 교통 데이터, 항공편 데이터, 교통사고 데이터 등 다양한 종류의 데이터 세트가 공개되어 있다. 국내 공공 데이터 포털에서는 다양한 교통 관련 데이터를 공개하고 있는데, 이를 인공지능 학습을 위한 데이터로 전환하기 위해서는 추가 자원 투입이 필요하다.
Reference 참고 문헌
1) Lana, I., et. al., "From Data to Actions in Intelligent Transportation Systems: A Perspective of Functional Requirements for Model Actionability," arXiv, Feb 8, 20212) 깃허브 주소는 https://github.com/waymo-research/waymo-open-dataset 이다.3) https://self-driving.lyft.com/level5/data/ 참고4) https://zarr.readthedocs.io/en/stable/ 참고5) https://www.nuscenes.org/nuscenes6) Kujala , R . et . al . , " A collection of public transport network data sets for 25 cities , " Scientific Data 5 , May 15 , 2018